



核心参数
初使容量
1<<4. 相当于2的四次方 默认16
最大容量
1<<30 相当于2的30次方 1073741824
加载因子
0.75f (16*0.75=12[如果size大于12 提前扩容])
为什么加载因子是0.75
加载因子越大,空间利用率就越高,index冲突的概率越大
加载因子越小(0.2),空间利用度不高,index冲突概率就比较小。
0.75科学计算:统计概率学(柏松分布式统计算法得出),
链表长度
8 大于8,转红黑树存储
红黑树个数
如果小于6 将红黑树转换为链表
数组长度
64(数组长度大于等于64并且链表长度大于8转换为红黑树存储)
modcount
防止遍历集合的时候 集合进行篡改。(新增报错fastclass机智)
loadFactor
加载因子 属性值
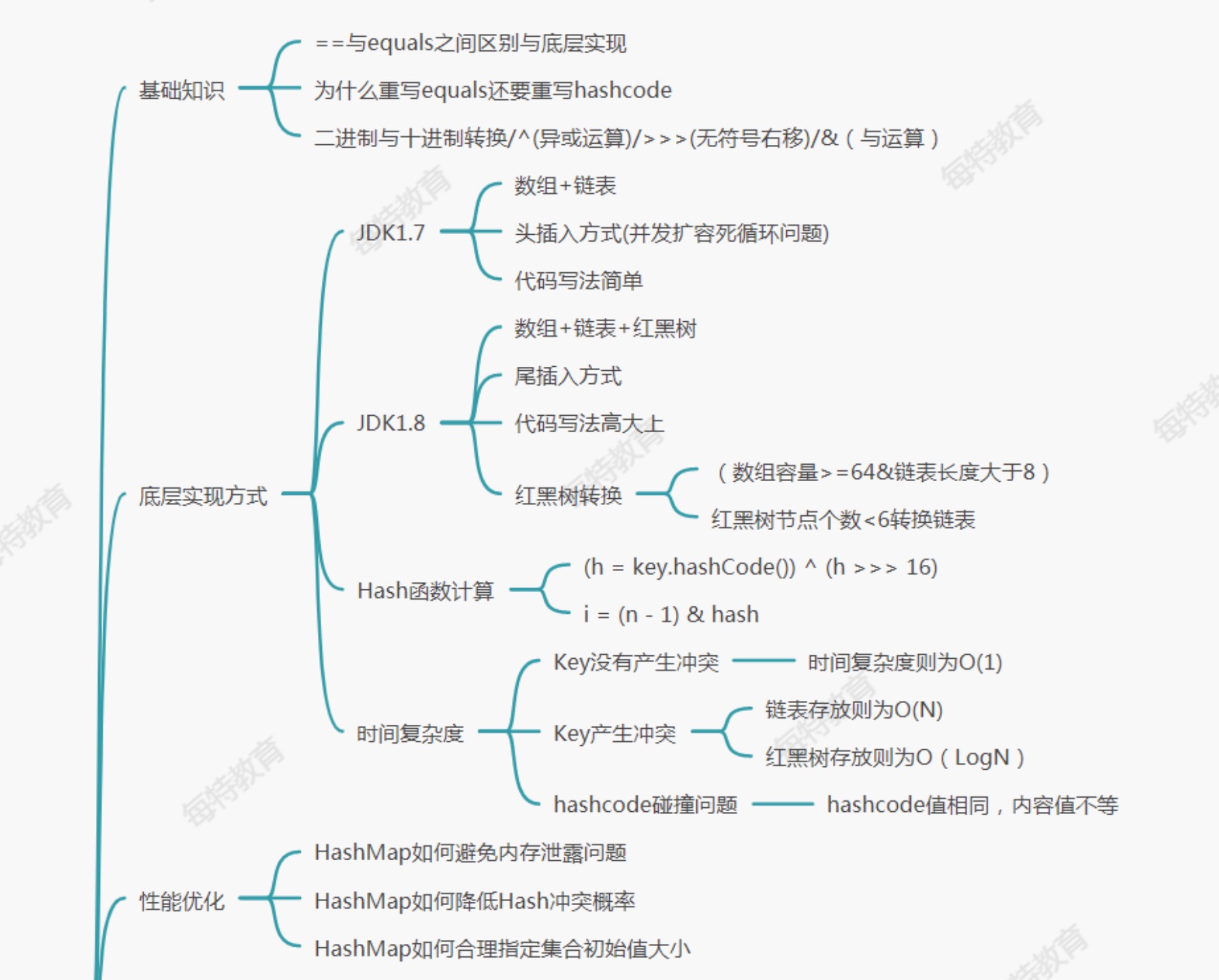
基础知识
1:为什么充血equals与hashcode方法
hashcode方法:
底层采用c语言编写。
根据对象内存地址,转换成整数类型。(hash碰撞)
equals方法:
如果说两个对象hashcode zhi相等,则对象的内容值不一定相等。如果使用equals方法,去比较两个对象的内容,相等的情况下,则hashcode一定相等。
注意:
equals默认使用的是 物理地址。一些类会重写equals方法。
hashmap底层就是通过equals和hash 包括set集合。
string类重写了equals 方法
如何避免hashmap内存泄露
hashmap集合中是否可以存放自定义对象作为key?可以的
自定义对象作为key的时候, 一定要重写对象的hashcode方法和hashcode方法,保证对象key不重复创建。
时间复杂度
o(1):只需要查询一次,使用数组index查找。
o(n):循环从头查询尾部
o(longn):平方 二插树,红黑树 效率还可以
hashmap
hashmap与hashtable区别
hashmap线程不安全。允许存放key为null,hashtable不允许。
hashmap底层如何实现
hashmap. put底层
定义了node节点,并且定义了n(表单当前数组的长度)与i(index下标位就是key),以及临时的 tab与table大小接受。
首先将全局的table赋予tab,如果为null或者长度等于0,开始对table作为扩容。(懒加载)默认扩容大小为16。
1:基于arraylist集合方式实现
优点:不需要考虑hash碰撞
缺点:查询效率慢,时间复杂度是O(n)
package com.gtf.fs;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class ArrayListMap<k,v> {
private List<Map.Entry<k,v>> entrys=new ArrayList<>();
class entry<K,V> {
K k;
V v;
public entry (K k,V v) {
this.k = k;
this.v = v;
}
}
public void put(k k,v v) {
entrys.add((Map.Entry<k, v>) new entry(k,v));
}
public v get(k k) {
for (Map.Entry<k,v> entry : entrys) {
if (entry.getKey() == k) {
System.out.println(entry.getValue());
}
}
return null;
}
}
2:基于数组+链表方式(1.7)
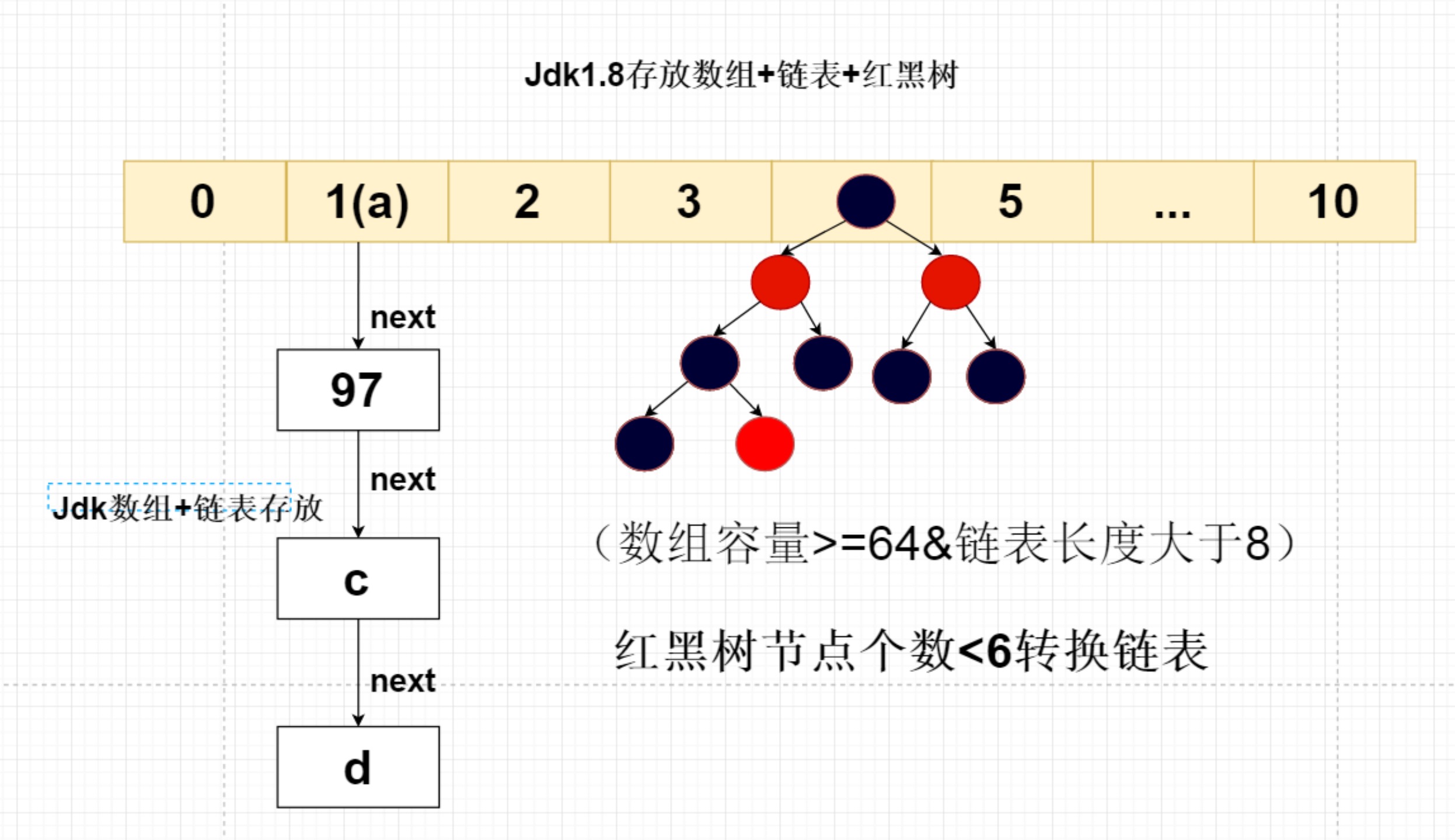
数组扩容问题。默认16
package com.gtf.map;
import java.util.Map;
import static java.util.Objects.hash;
public class ExpHaspMap<K, V> {
/**
* 默认 16大小
*/
private Entry[] entrys = new Entry[16];
/**
* 数组+脸表
*
* @param <K>
* @param <V>
*/
class Entry<K, V> {
K k;
V v;
Entry<K, V> next;
public Entry(K k, V v) {
this.k = k;
this.v = v;
}
}
public void put(K k, V v) {
//根据key的hash值计算出数组的下标 ,但是a和97hash值一样,所以这个是有问题的
int index = k==null?0: k.hashCode() % entrys.length;
//判断数组中是否有这个key
Entry oldEntry = entrys[index];
if (oldEntry == null) {
//key没有发生 hash碰撞
entrys[index] = new Entry(k, v);
} else {
//key发生hash碰撞
oldEntry.next = new Entry(k, v);
}
// entrys[index] = new Entry<K, V>(k,v);
}
public V get(K k) {
int index = k==null?0: k.hashCode() % entrys.length;
Object v = entrys[index].v;
for (Entry entry = entrys[index]; entry != null; entry = entry.next) {
if ((k==null&&entry.next==null) ||entry.next.equals(k) ) {
return (V) entry.v;
}
}
return null;
}
}
3:基于数组+链表方式+红黑树(1.8)
HashMap如何降低Hash冲突概率
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
((p = tab[i = (n - 1) & hash])
1、保证不会发生数组越界
首先我们要知道的是,在HashMap,数组的长度按规定一定是2的幂。因此,数组的长度的二进制形式是:10000…000, 1后面有偶数个0。 那么,length - 1 的二进制形式就是01111.111, 0后面有偶数个1。最高位是0, 和hash值相“与”,结果值一定不会比数组的长度值大,因此也就不会发生数组越界。一个哈希值是8,二进制是1000,一个哈希值是9,二进制是1001。和1111“与”运算后,结果分别是1000和1001,它们被分配在了数组的不同位置,这样,哈希的分布非常均匀。
为什么hashmap是无序集合
散列,将所有的链表和红黑树都实现遍历。
LinkedHashMap:有序的hashMap
使用双向链表存储。
将每个index的链表进行关联。效率比hashmap低一点。
LinkedHashMap实现缓存淘汰框架
LRU(最近少使用)缓存淘汰算法
LFU(最不经常使用算法)缓存淘汰算法
ARC(自适应缓存替换算法)缓存淘汰算法
FIFO(先进先出算法)缓存淘汰算法
MRU(最近最常使用算法)缓存淘汰算法
LinkedHashMap基于双向链表实现,可以分为插入或者访问顺序两种,采用双链表的形式保证有序
可以根据插入或者读取顺序
LinkedHashMap是HashMap的子类,但是内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于双向链表中。LinkedHashMap支持两种顺序插入顺序 、 访问顺序
插入顺序:先添加的在前面,后添加的在后面。修改操作不影响顺序
执行get/put操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始的是最久没有被访问的,这就是访问顺序。
其中参数accessOrder就是用来指定是否按访问顺序,如果为true,就是访问顺序,false根据新增顺序
public static void main(String[] args) {
LinkedHashMap<String, String> stringStringLinkedHashMap = new LinkedHashMap<String, String>(16, 0.75f, true);
stringStringLinkedHashMap.put("a", "a");
stringStringLinkedHashMap.put("b", "b");
stringStringLinkedHashMap.put("c", "c");
stringStringLinkedHashMap.get("b");
stringStringLinkedHashMap.get("a");
stringStringLinkedHashMap.forEach((k, v) -> System.out.println(k + ":" + v) );
}
手写LRU缓存算法
package com.gtf.text;
import java.util.LinkedHashMap;
public class LruLinkedHaspMap<K, V> extends LinkedHashMap<K, V> {
/**
* 容量
*
* @param capacity
*/
private int capacity;
public LruLinkedHaspMap(int capacity) {
super(capacity, 0.75f, true);
this.capacity = capacity;
}
/**
* 当缓存中的数量大于容量时,返回true
* size() > capacity;清理头节点
*/
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
return size() > capacity;
}
public static void main(String[] args) {
LruLinkedHaspMap<String, String> lruLinkedHaspMap = new LruLinkedHaspMap<>(3);
lruLinkedHaspMap.put("a", "1");
lruLinkedHaspMap.put("b", "1");
lruLinkedHaspMap.put("c", "1");
lruLinkedHaspMap.get("a");
lruLinkedHaspMap.put("d", "1");
lruLinkedHaspMap.forEach((k, v) -> System.out.println(k + ":" + v));
}
}
常见问题
hashmap如何存储大量的key (1w)
集合初始化的时候,指定集合初始化大小。(存储的数据/0.75)+1
目的:减少底层扩容次数。
1.7hashmap与1.8有什么区别
- hashmap1.7
-
- 是数组+链表 时间复杂度o(1)
-
- 采用头插入法 写法 简单 (多线程情况下:死循环问题)
-
- 原来的链表都会迁移到新table的 同一个链表中
- hashmap1.8
- -数组+链表+红黑树 时间复杂度 o(logn)
-
- 采用尾插入法 写法高大上 解决死循环问题
-
- 原来的链表使用与运算 hash与原来table长度 拆分成两个链表 放入table 中,将链表长度缩短,能够提高查询效率
-
- 能够降低key对于的index冲突概率 提高查询效率