



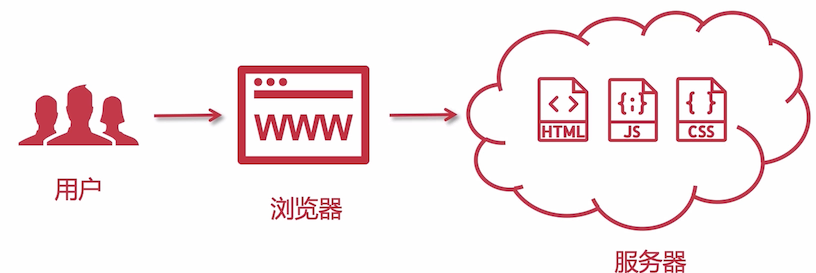
Web 1.0 时代,几乎所有网站都是静态网站,没有和用户有什么交互,主要用于给用户展示内容。
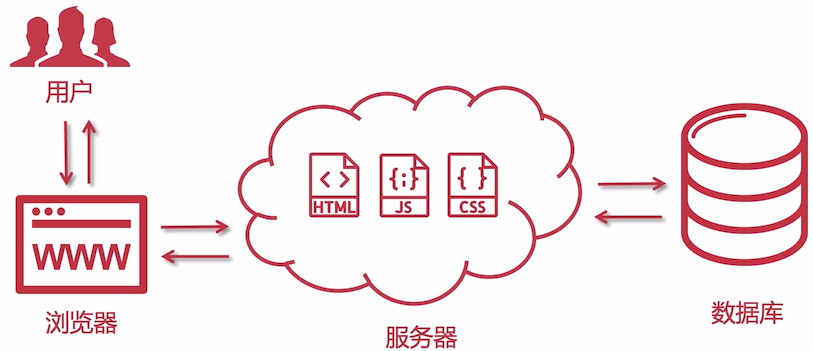
Web 2.0 时代,用户与服务器双向交互,增加删除修改数据,这些数据保存在数据库中
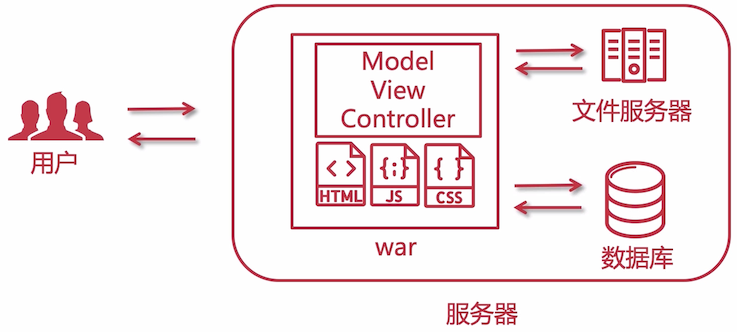
最初的单体架构 ,用户访问服务器,服务器中部署有项目(war ),这个时候的访问量也不是很大,只需要一台服务器即可;
文件服务器和数据库也是部署在这一台服务器上的。
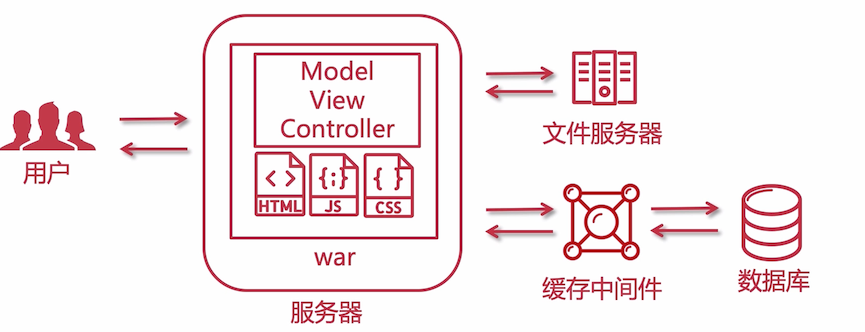
最初的分离模式: 随着服务的发展,用户越来越多,一台服务器是不能满足所有用户的需求,最常见的问题是会导致空间不足,无论是图片还是数据库都显得乏力。
这个时候,将 web、文件服务器、数据库都分开部署,就解决了空间和服务器性能的问题
随着时间的推移,用户成倍的增加,数据库的压力也会增加,可能导致用户查询响应的延迟。
这个时候就加入了 缓存中间件 缓存一些查询结果,这样一来绝大部分的查询请求都会落在缓存中间件上,而不是数据库了,解决了数据库响应延迟的问题
目前所有节点都是单节点部署,如果挂掉,那么所有的服务将不可使用,就存为了企业的瓶颈。
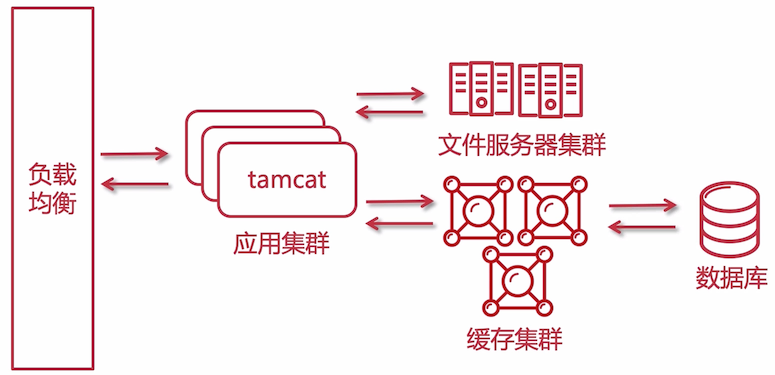
引入 **应用集群 **(所有节点的应用内容都是一样的)+ 负载均衡 的概念,提升整个系统的性能,不止是应用可以做集群,文件服务器也可以做集群,这样一来,当某一个节点挂掉的时候,还有其他的节点提供服务。
在当前时期,数据库还是单库,不会做集群
前面虽然用到了一些缓存,但是还是有部分读操作落在数据库上,当用户超过百万、千万级别时,数据库的负载能力就成为了网站的瓶颈
几乎上是二八原则,80% 读,20% 写,当读写都在数据库时,单体数据库的性能就很低了。
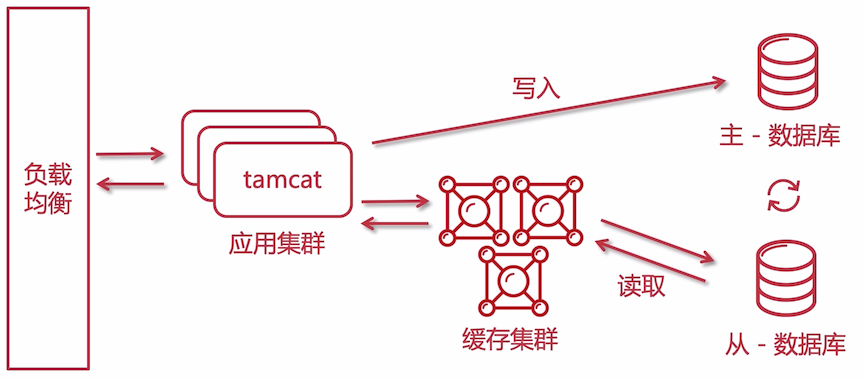
此时就是一个 读写分离的架构,写主库,读从库,会定时的从主库中把数据同步到从库中。
这些改动对用户是透明的,他们只知道访问快就行了。
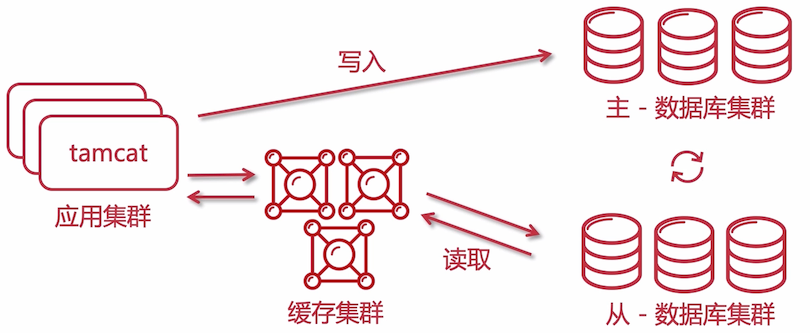
一个大型网站的业务增长也是很快的,虽然做了读写分离,但是当数据库撑不住的时候,就需要使用 分库分表的架构 了
将单个数据库分成多个数据库,同一个表的数据散列在多个库中,此种架构是对数据库的最后手段,只有在数据非常非常庞大的时候才会考虑。
一般来说:单表的数据达到 700~800 万,就需要考虑这样做了,因为数据库的性能会急剧下降。
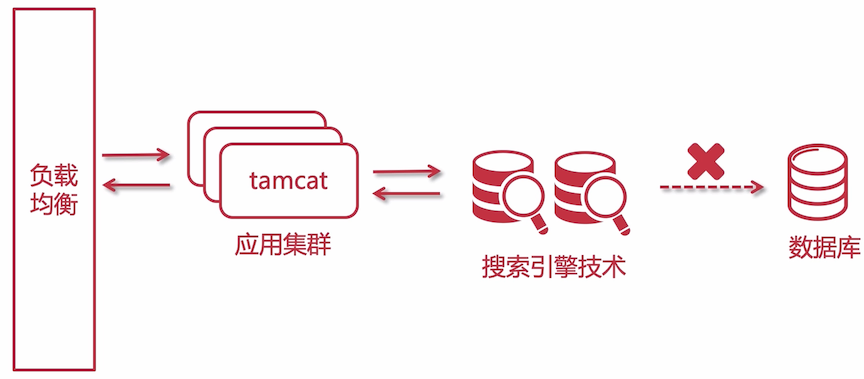
随着网站的发展,用户对数据的检索可能会出现多样化,数据库可能就不满足了,可以引入 搜索引擎技术
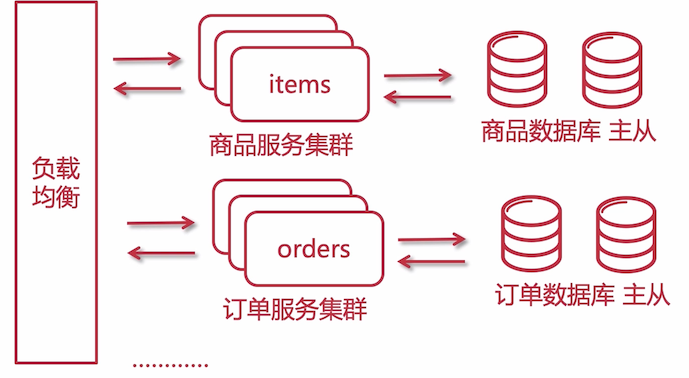
对于大型网站的业务是非常非常复杂的,所谓合久必分,当业务处于非常非常复杂的时候,可以将一个大业务拆分成一个个独立的子系统
此时的架构则是 微服务阶段,而前面讲解的单体架构中的各种手段,包括缓存应用集群、数据库集群也可以在这个子系统上使用。
当将多个子系统整合在一起的时候就组成了一个大型的系统,对运维来说是个不小的挑战。
优点:复杂降低;缺点:代码比较复杂,运维繁琐复杂,分布式事务也需要考虑
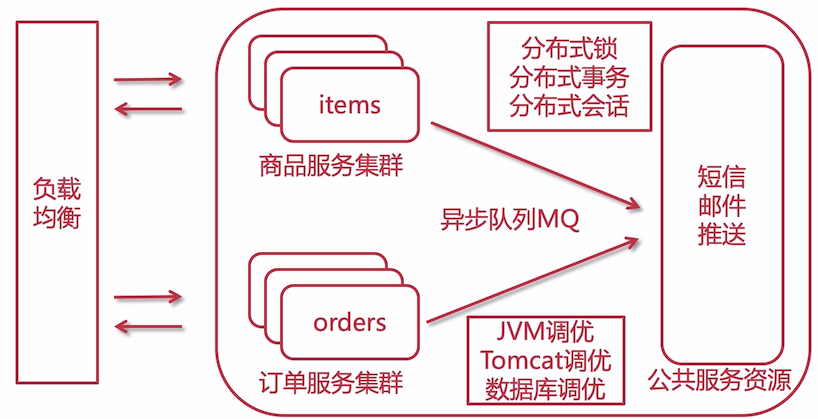
可以看到,我们需要考虑和解决的问题就变多了,公共服务、异步队列调用、分布式锁、分布式事物、分布式会话等等问题。
当规模达到此步骤的时候,绝大部分的问题就都得到了解决。以上演进历程是绝大多数公司的一个演进历程,但是这个不是标准的,不是说必须要在某一个阶段的时候才能使用其中的一些知识点。
- Web 1.0 时代
没有交互,只展示内容 - Web 2.0 时代
有了一定的交互 - 最初的单体架构
访问量不大,所有应用用到的相关资源都在一台服务器上 - 最初的分离架构
将不同的资源,如文件存储服务、数据库服务分开部署,让这些应用能获得更多的机器资源 - 缓存架构
当用户增多,查询变多变延迟的时候,加入缓存,拦截掉大部分的查询请求,降低数据库的负载 - 集群架构
单体架构存在瓶颈,用户继续增多时,就需要使用集群来承担更多的访问请求 - 数据库读写分离架构
业务不断的增长,用户也不断的增长,数据库,数据库负载又称为了瓶颈,使用读写分离架构 - 分库分表架构
业务继续发展,当数据量很庞大的时候,单库无法容纳下了,则使用分库分表,这是对数据库的最后一步 - 搜索引擎技术
随着发展,用户对搜索有了多用性,传统的数据库模糊搜索可能就不能满足了,引入搜索引擎技术 - 微服务架构
当业务发展到了一个非常非常复杂的阶段时,就将复杂业务拆分成一个一个独立的子系统来处理。形成了微服务架构