



什么是stream流
Stream 是JDK1.8 中处理集合的关键抽象概念,Lambda 和 Stream 是JDK1.8新增的函数式编程最有亮点的特性了,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用SQL执行的数据库查询。Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
Stream :非常方便精简的形式遍历集合实现 过滤、排序等。
Mysql:select userName from mayikt where userName =‘mayikt’
Order by age limt(0,2)
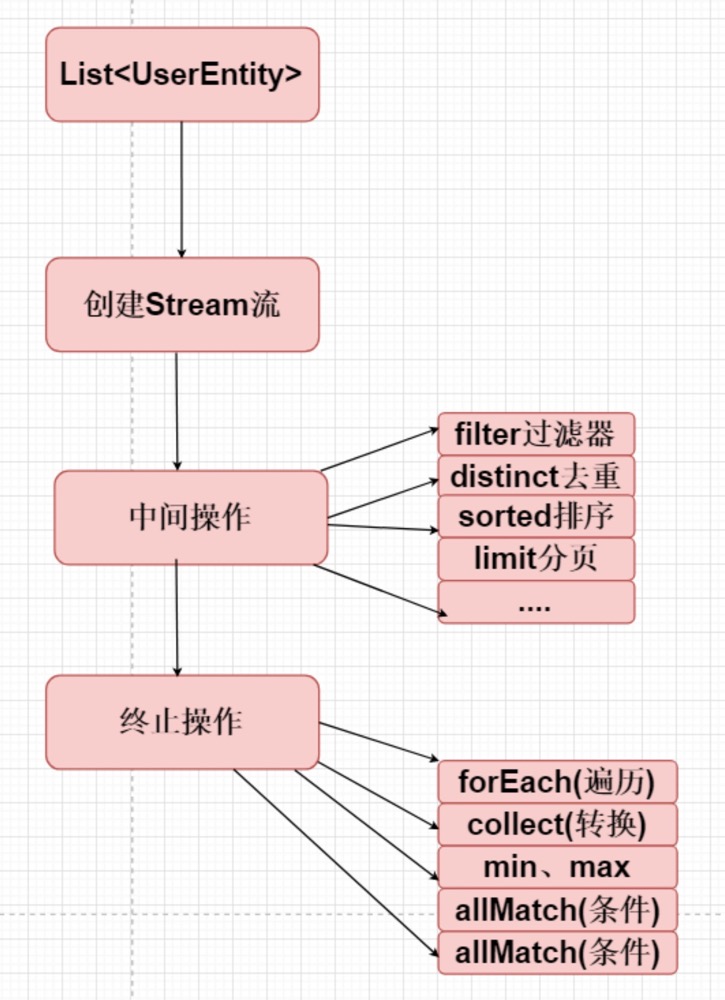
Stream创建方式
parallelStream为并行流采用多线程执行
Stream采用单线程执行
parallelStream效率比Stream要高。
Stream将list转换为Set
ArrayList<UserEntity> userEntities = new ArrayList<>();
userEntities.add(new UserEntity("11", 20));
userEntities.add(new UserEntity("11", 20));
userEntities.add(new UserEntity("22", 35));
userEntities.add(new UserEntity("223", 16));
userEntities.add(new UserEntity("33", 16));
//串形流
Stream<UserEntity> stream = userEntities.stream();
//转set集合
Set<UserEntity> collect = stream.collect(Collectors.toSet());
//打印集合,但是没去重复,需要重写eques方法
collect.forEach(collect1 -> System.out.println(collect1));
Stream将list转换为Map
public static void main(String[] args) {
ArrayList<UserEntity> userEntities = new ArrayList<>();
userEntities.add(new UserEntity("11", 20));
userEntities.add(new UserEntity("111", 21));
userEntities.add(new UserEntity("22", 35));
userEntities.add(new UserEntity("223", 16));
userEntities.add(new UserEntity("33", 16));
//串形流
Stream<UserEntity> stream = userEntities.stream();
//转map集合
Map<String, Integer> collect = stream.collect(Collectors.toMap(UserEntity::getName, UserEntity::getAge));
//打印集合,但是没去重复,需要重写eques方法
collect.forEach((k, v) -> System.out.println(k + ":" + v));
// //并行流
// userEntities.parallelStream();
}
Stream将Reduce 求和
public static void main(String[] args) {
ArrayList<UserEntity> userEntities = new ArrayList<>();
userEntities.add(new UserEntity("11", 20));
userEntities.add(new UserEntity("111", 21));
userEntities.add(new UserEntity("22", 35));
userEntities.add(new UserEntity("223", 16));
userEntities.add(new UserEntity("33", 16));
Stream<UserEntity> stream = userEntities.stream();
Optional<UserEntity> reduce = stream.reduce((user1, user2) -> {
user1.setAge(user1.getAge() + user2.getAge());
return user1;
});
System.out.println(reduce.get());
}
StreamMatch 匹配
anyMatch表示,判断的条件里,任意一个元素成功,返回true
allMatch表示,判断条件里的元素,所有的都是,返回true
noneMatch跟allMatch相反,判断条件里的元素,所有的都不是,返回true
public static void main(String[] args) {
ArrayList<UserEntity> userEntities = new ArrayList<>();
userEntities.add(new UserEntity("11", 20));
userEntities.add(new UserEntity("11", 20));
userEntities.add(new UserEntity("22", 35));
userEntities.add(new UserEntity("223", 16));
userEntities.add(new UserEntity("33", 16));
Stream<UserEntity> stream = userEntities.stream();
boolean b = stream.anyMatch(userEntity -> userEntity.getName() .equals("11"));
boolean b = stream.noneMatch(userEntity -> userEntity.getName() .equals("11"));
boolean b = stream.allMatch(userEntity -> userEntity.getName() .equals("11"));
System.out.println(b);
}
Stream过滤器
public static void main(String[] args) {
ArrayList<UserEntity> userEntities = new ArrayList<>();
userEntities.add(new UserEntity("11", 20));
userEntities.add(new UserEntity("11", 23));
userEntities.add(new UserEntity("22", 35));
userEntities.add(new UserEntity("223", 16));
userEntities.add(new UserEntity("33", 16));
Stream<UserEntity> stream = userEntities.stream();
stream.filter(userEntity -> userEntity.getName().equals("11") && userEntity.getAge() > 20).forEach(System.out::println);
}
Stream limit和skip
Limit 从头开始获取
Skip 就是跳过
public static void main(String[] args) {
ArrayList<UserEntity> userEntities = new ArrayList<>();
userEntities.add(new UserEntity("11", 20));
userEntities.add(new UserEntity("11", 23));
userEntities.add(new UserEntity("2211", 35));
userEntities.add(new UserEntity("2213", 16));
userEntities.add(new UserEntity("311113", 16));
userEntities.add(new UserEntity("1112213211", 20));
userEntities.add(new UserEntity("13213121", 23));
userEntities.add(new UserEntity("224431312", 35));
Stream<UserEntity> stream = userEntities.stream();
stream.skip(1).limit(5).forEach(System.out::println);
}
Stream排序 sorted
public static void main(String[] args) {
ArrayList<UserEntity> userEntities = new ArrayList<>();
userEntities.add(new UserEntity("11", 20));
userEntities.add(new UserEntity("11", 23));
userEntities.add(new UserEntity("2211", 35));
userEntities.add(new UserEntity("2213", 16));
userEntities.add(new UserEntity("311113", 16));
userEntities.add(new UserEntity("1112213211", 20));
userEntities.add(new UserEntity("13213121", 23));
userEntities.add(new UserEntity("224431312", 35));
Stream<UserEntity> stream = userEntities.stream();
//升序
stream.sorted((o1, o2) -> o1.getAge() - o2.getAge()).forEach(System.out::println);
//降序
stream.sorted((o1, o2) -> o2.getAge() - o1.getAge()).forEach(System.out::println);
}
Stream 综合案例
public static void main(String[] args) {
ArrayList<UserEntity> userEntities = new ArrayList<>();
userEntities.add(new UserEntity("11", 20));
userEntities.add(new UserEntity("11", 23));
userEntities.add(new UserEntity("2211", 35));
userEntities.add(new UserEntity("2213", 16));
userEntities.add(new UserEntity("311113", 16));
userEntities.add(new UserEntity("1112213211", 20));
userEntities.add(new UserEntity("13213121", 23));
userEntities.add(new UserEntity("224431312", 35));
Stream<UserEntity> stream = userEntities.stream();
//对数据流进行降序排序,且名称要有包含11 并且获取1位
stream.sorted((o1, o2) -> o2.getAge() - o1.getAge()).filter(userEntity -> userEntity.getName().contains("11")).limit(1).forEach(System.out::println);
}
并行流与串行流区别
串行流:单线程的方式操作; 数据量比较少的时候。
并行流:多线程方式操作;数据量比较大的时候,原理:
Fork join 将一个大的任务拆分n多个小的子任务并行执行,
最后在统计结果,有可能会非常消耗cpu的资源,确实可以
提高效率。
注意:数据量比较少的情况下,不要使用并行流。